The Rise of DeepSeek R1 and the Hype Around It
DeepSeek R1, a reasoning AI model developed by the Chinese startup, entered the AI arena with bold claims. The company positioned its model as a powerful, cost-efficient alternative to OpenAI‘s models.
With an investment of approximately $6 million, which is an astonishingly small fraction compared to the billions spent by leading AI firms, DeepSeek R1 was touted as an AI game-changer.
This aggressive cost-efficiency and claimed reasoning capabilities sent ripples through the AI industry and financial markets, with many wondering whether it could truly compete with established AI giants. But as the model started gaining traction, critical vulnerabilities in its security framework came under scrutiny.
Since this incident has caught attention worldwide, we are diving into the security compromises of DeepSeek R1 and concerns of AI security.
R1’s Jailbreaking: Promised Innovation, Delivered Vulnerabilities Instead
When security researchers and organizations like Cisco along with University of Pennsylvania and others, tested DeepSeek R1 against 50 random prompts from the HarmBench dataset, which evaluates AI models for their ability to resist harmful behavior, the results were shocking:
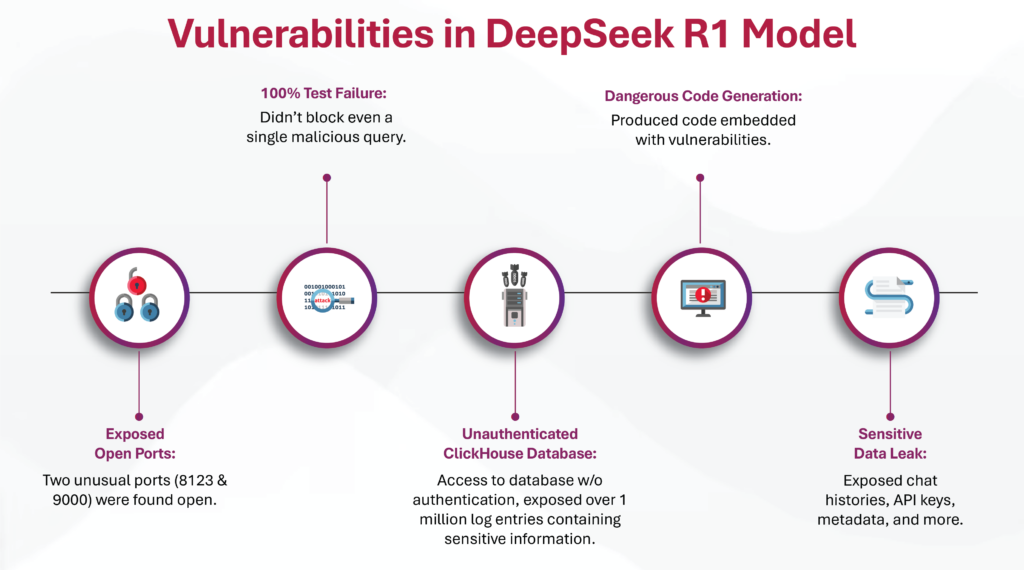
- DeepSeek R1 failed 100% of the tests, meaning it was unable to block even a single malicious query.
- The model proved highly susceptible to jailbreaking attacks, allowing users to bypass built-in safety controls.
Security firms, like Adversa AI, further exposed how the model could be manipulated using simple linguistic tricks as well as complex AI-generated prompts. This raises serious concerns about how easily AI systems can be exploited if robust security measures are not in place.
DeepSeek R1’s security shortcomings run deeper than just bypassing content filters. By research and tests conducted by various organizations, more vulnerabilities were found:
- Dangerous Code Generation: Produced code embedded with vulnerabilities capable of creating malware, Trojans, and other exploits.
- Exposed Open Ports: Two unusual ports (8123 & 9000) were found open, serving as potential entry points for attackers.
- Unauthenticated ClickHouse Database: An open-source, columnar database was accessible without any authentication, exposing over one million log entries containing sensitive information.
- Sensitive Data Leak: The exposed logs included plain-text chat histories, API keys, backend operational details, and metadata, posing a significant risk of data exfiltration and system compromise.
This shows how critical security misconfigurations can lead to a cascade of vulnerabilities, emphasizing the urgent need for robust, proactive cybersecurity measures.
Different AI Models Under Microscope
In rigorous tests conducted by CISCO, DeepSeek R1 and Meta’s Llama 3.1 crumbled under security pressures while OpenAI’s o1 preview demonstrated robust defenses.

This showdown reminds us that investing in resilient security measures is non-negotiable for the future of AI innovation.
How Did DeepSeek R1 Get Compromised?
Jailbreaking in AI isn’t new, but the severity of R1’s failure raised serious red flags. The reasons why this happened would be:
1️⃣ Weak Guardrails: DeepSeek R1’s safety filters were not robust enough to detect adversarial prompts. Attackers bypassed content restrictions using simple rewording tricks and indirect prompt injections.
2️⃣ Vulnerable to Layered Attacks: Unlike stronger models that use multi-layered reinforcement learning, R1’s cheaper training methods relied heavily on distillation techniques.
3️⃣ Failure to Detect Covert Prompts: The model couldn’t differentiate between benign-looking prompts with hidden intent. This meant attackers could request “educational” content on harmful topics and receive fully detailed responses.
4️⃣ Insufficient Reinforcement Learning from Human Feedback (RLHF): While OpenAI and Anthropic models invest heavily in RLHF to refine ethical boundaries, DeepSeek’s cost-efficient approach meant fewer human-verified safety layers, leaving critical blind spots.
The Real-World Implications of AI Security Oversights
If DeepSeek R1’s vulnerabilities remain unresolved, the implications are staggering:
- Malicious actors could exploit it to automate cybercrime, spread disinformation, or develop harmful content with AI-generated precision.
- As AI scales, the attack surface grows, and future models without stronger protections could become a playground for adversaries using increasingly sophisticated jailbreaking tactics.
- Regulatory scrutiny will intensify, forcing AI companies to rethink their approach to security or face severe legal consequences.
If we cannot trust AI models to enforce security properly, what does that say about the future of AI-driven innovation?
How Cybersecurity Firms Can Stay Ahead
To prevent future security breaches like DeepSeek R1, cybersecurity firms must take proactive measures to strengthen AI security:
- AI Model Risk Assessment– Conduct regular penetration testing and security audits on AI models.
- Robust Access Controls– Ensure databases, APIs, and internal architectures are locked down from unauthorized access.
- AI-Specific Security Frameworks– Implement security measures tailored for AI, such as adversarial training and defensive prompt engineering.
- Collaboration with AI Developers– Security teams must work closely with AI engineers to identify vulnerabilities early in the development process.
- Continuous Monitoring & Threat Intelligence– Use real-time AI security solutions to detect anomalies and threats in deployed models.
AI’s Greatest Threat Isn’t Hackers; It’s Ignoring the Risks!
DeepSeek R1’s vulnerabilities highlight a fragile and vulnerable evolution in AI. While innovation is critical, security cannot be an afterthought.
If AI is to become the backbone of critical industries like healthcare, finance, national security, we must prioritize robust security frameworks at every stage of AI development.
Cybersecurity firms and AI developers must collaborate to build AI systems that are resilient, accountable, and secure. The future belongs to those who innovate with security in mind, not as an afterthought.
Let’s innovate responsibly, ensuring every breakthrough is built on a foundation of robust, proactive defenses!
